Beste AydemirI am an MSc student in Data Science at Ludwig-Maximilian University of Munich. My research interests are vision language models and their applications to embodied agents and autonomous driving. |

|
Education

|
Ludwig Maximilian University of Munich Master of Science in Data Science, GPA: 1.3 (1 is the best)
|

|
Bilkent University Bachelor of Science in Electrical and Electronics Engineering (Comprehensive Scholarship); GPA: 3.68/4
|
Projects
|
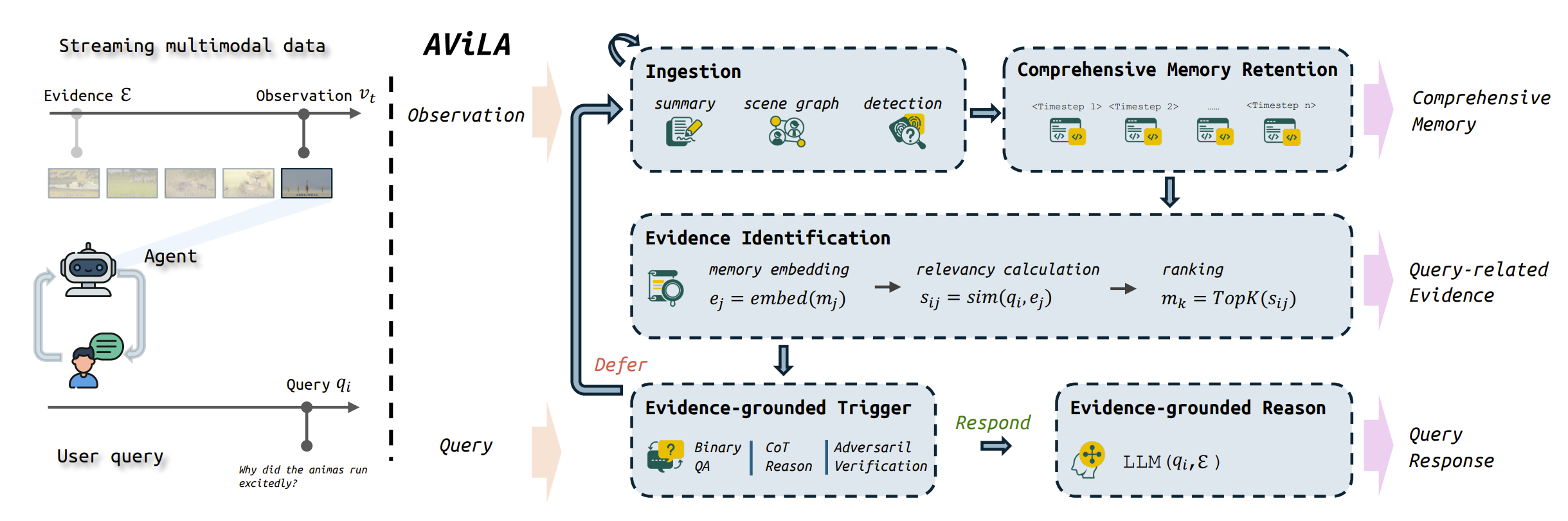
AViLA: Asynchronous Vision-Language Agent
arXiv Paper
|
|
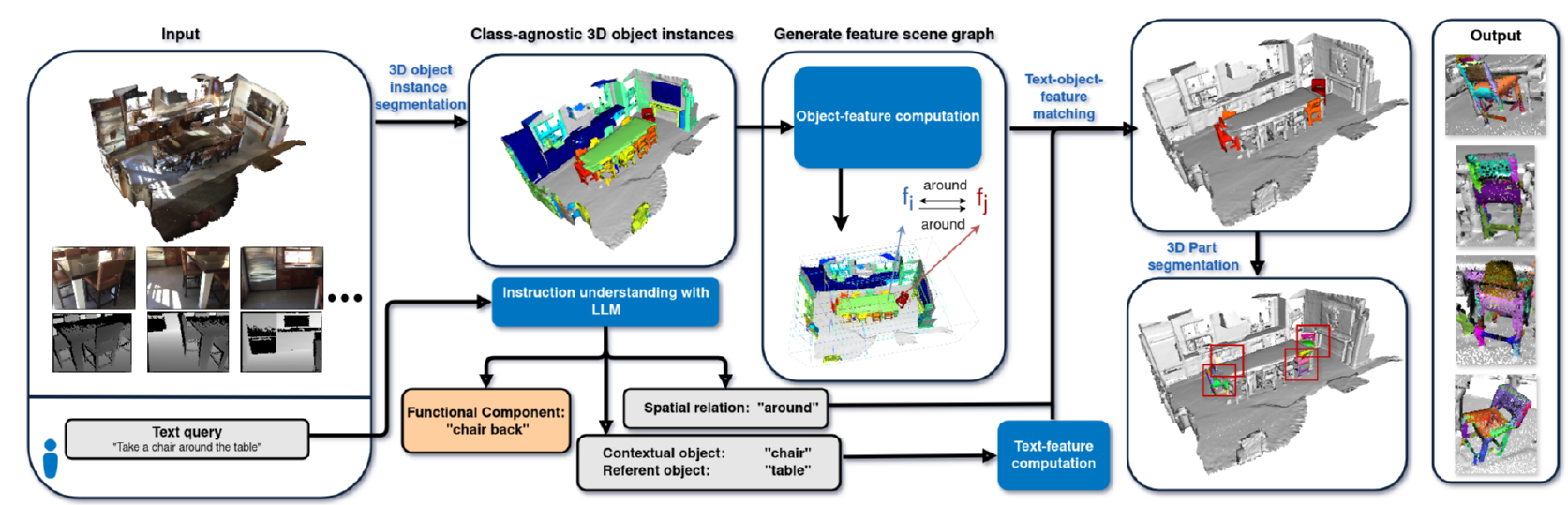
Navigation and Manipulation with Vision-Language Models
Collaboration between Technical University of Munich (TUM) and Oxford University Report
|
|
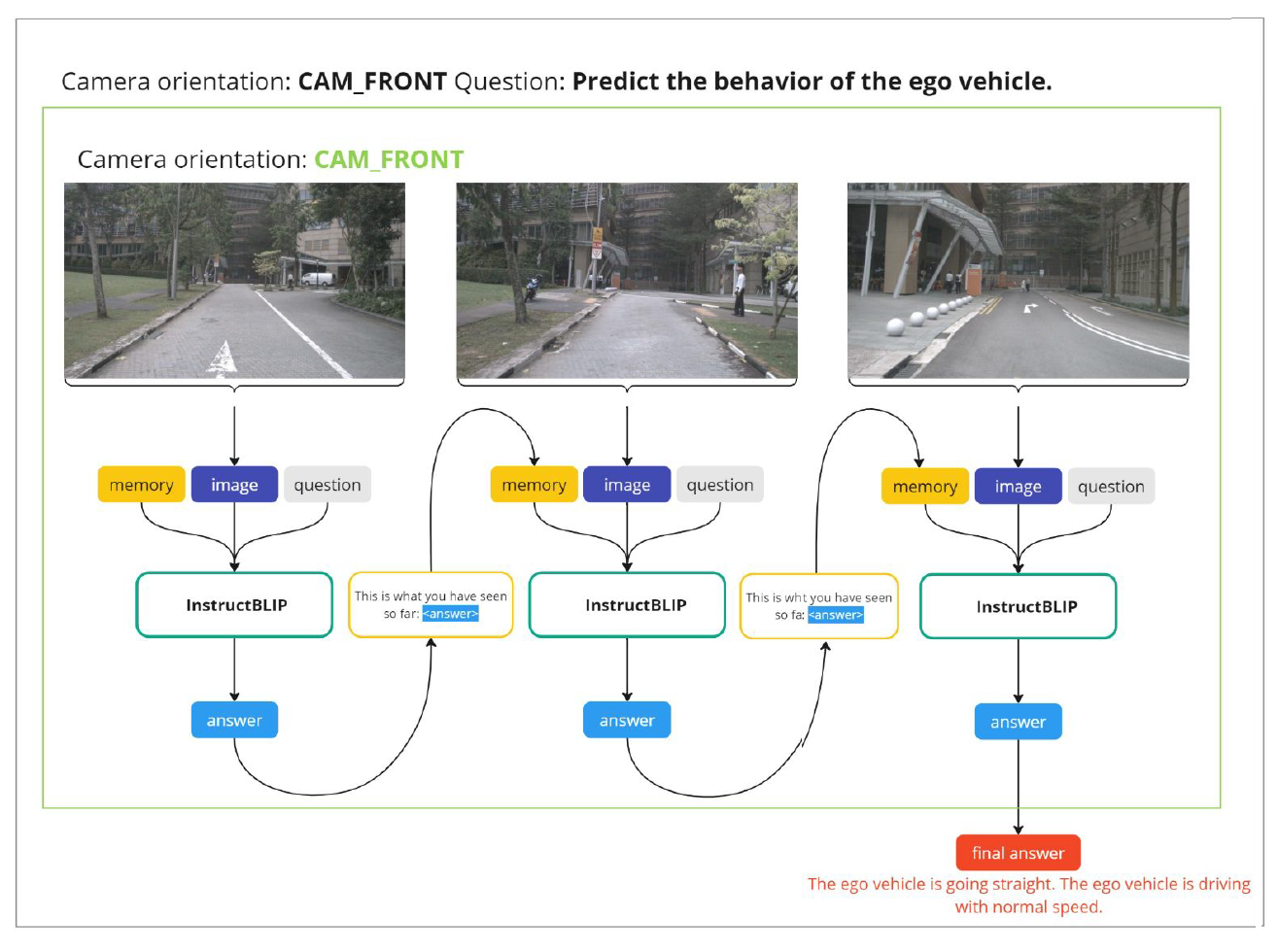
Autonomous Driving LLM-based Agent in Streaming Videos
Report
|
|
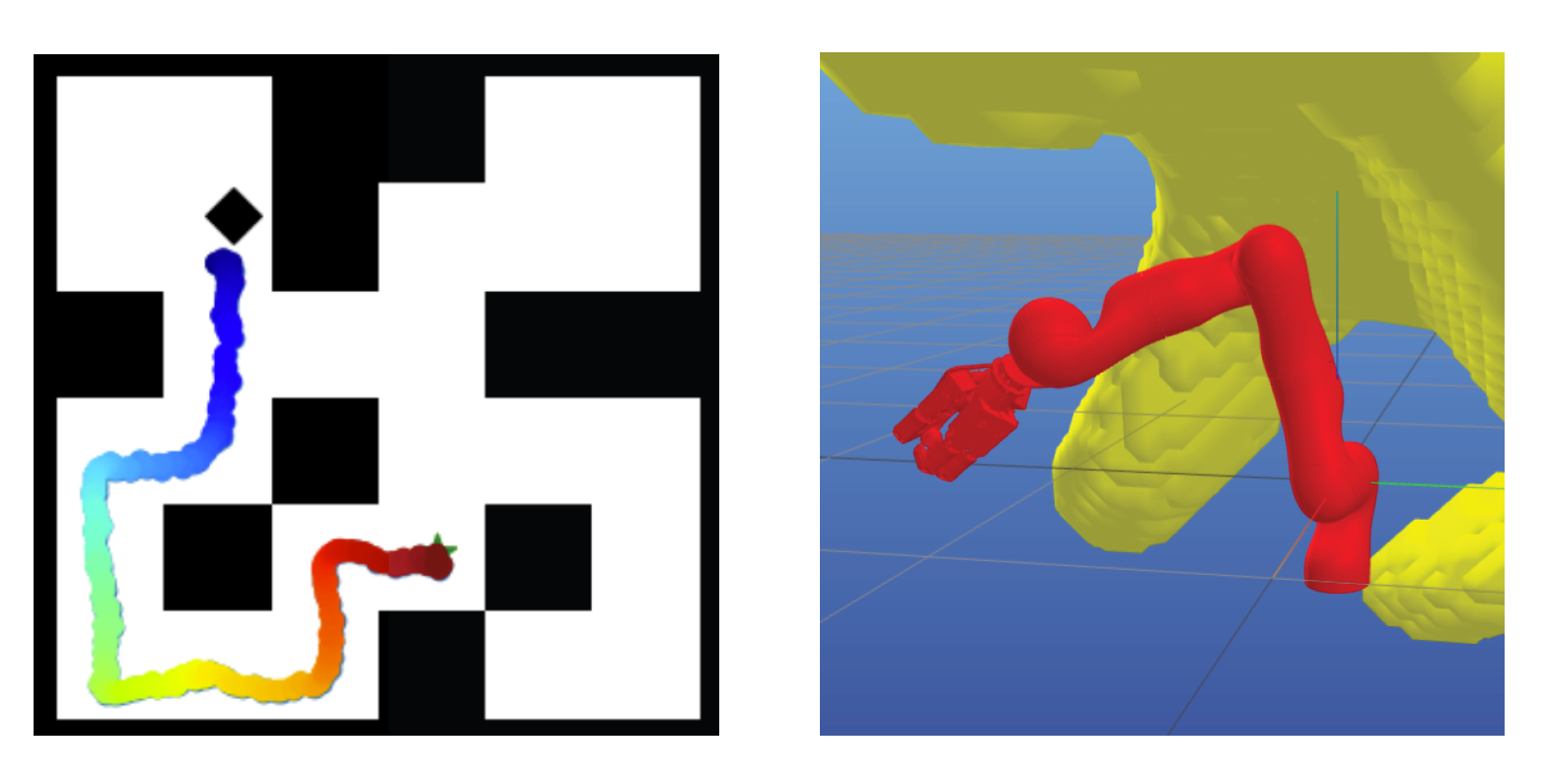
Diffusion Robot Path Planning
Project Poster
|
Experience

|
Huawei Munich Research Center Student Worker (November 2024 - April 2025)
|

|
Fraunhofer Student Worker (November 2023 - November 2024)
|

|
The University of Edinburgh Student Researcher (June 2020 - April 2024, Online)
|
|
Design and source code from Jon Barron's website |